 I have mentored quite a few VCDX candidates over the past year and the biggest weakness I see (and I was no different) is how Recoverability impacts Availability. In particular, the relationship of SLAs to BC/DR and Backup/Recovery.
I have mentored quite a few VCDX candidates over the past year and the biggest weakness I see (and I was no different) is how Recoverability impacts Availability. In particular, the relationship of SLAs to BC/DR and Backup/Recovery.
List of articles in my VCDX Deep-Dive series (more than 70 posts)
The first thing to clearly understand, is what are you protecting against and what Availability level are you committing to deliver? Every design decision you make must relate back to the answers of those two questions.
UPDATE: The five infrastructure design qualities are: Availability, Manageability, Performance, Recoverability and Security. This post focuses on understanding how Recoverability impacts Availability. Thanks to Matt Vandenbeld for highlighting that.
Here is a sample diagram that will make sense as you read this article. You should also build a similar big picture view to fully understand your design.
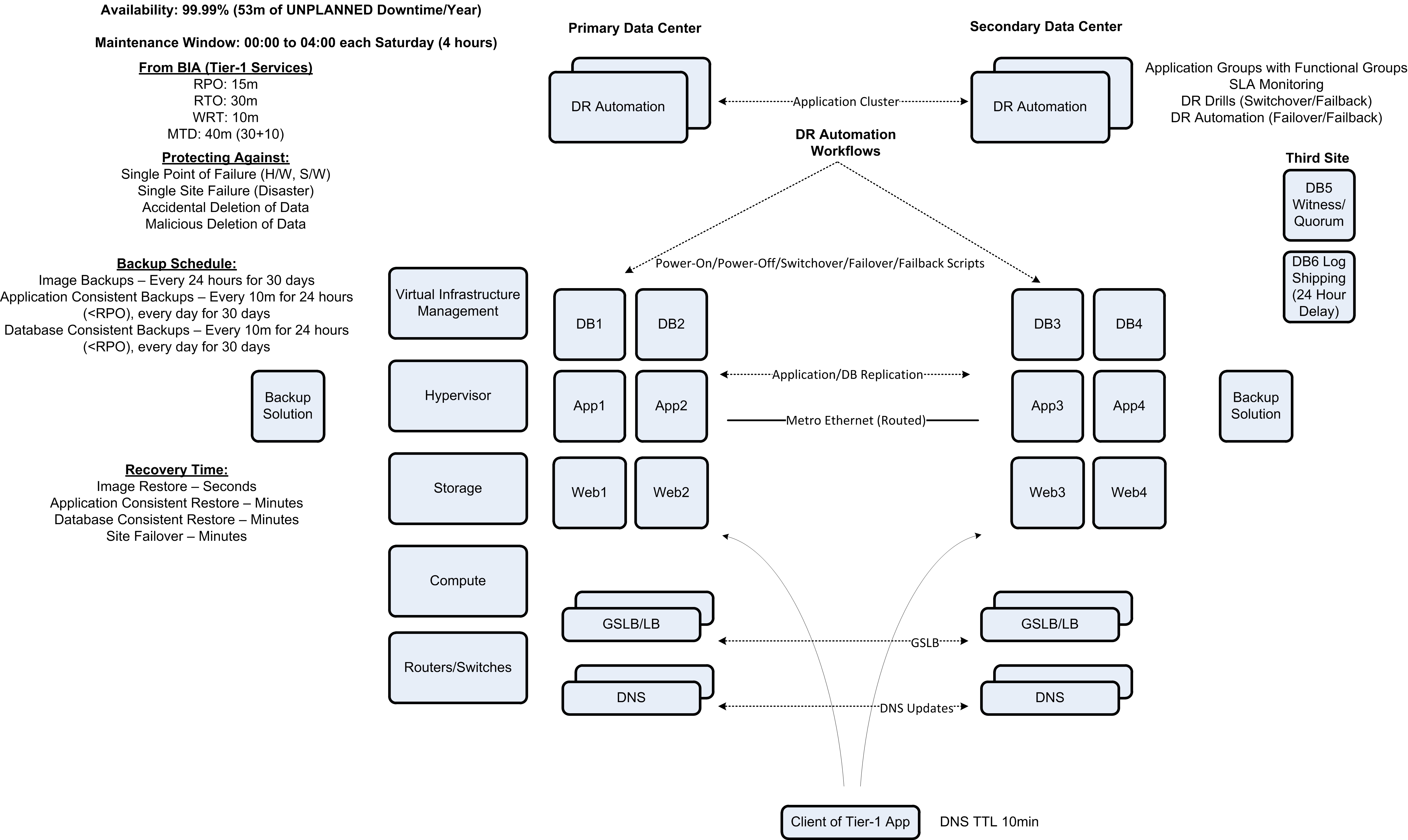 Availability
Availability
Business people understand nines of availability, which translate into the following:
- Two 9’s – 99% = 3.65 days of downtime per year (Easier to achieve, less expensive)
- Three 9’s – 99.9% = 8.76 hours of downtime per year
- Four 9’s – 99.99% = 52.6 minutes of downtime per year
- Five 9’s – 99.999% = 5.26 minutes of downtime per year (Very difficult to achieve, very expensive)
You need to make sure that planned downtime is not included in the SLA. If you assume it is not, then you may have a nasty surprise coming your way (more on that in the next section).
The other subtlety to classify, does the SLA apply during business hours only or 24×365?
Planned Maintenance Windows
Every service must have planned downtime for maintenance. If you do not take this into account, then you will break your SLA, which translates into bad design and an unhappy customer.
A typical maintenance window is 4 hours per week after business hours of the last day of the week or on the first day of the weekend. The theory being, you have more time to fix any mistakes before your business week begins again.
Business Impact Analysis (BIA)
The BIA calculates the cost of a service being down (per hour) and allows the business to translate that loss of service into an acceptable risk that becomes your SLA. Instead of nines of availability, a more precise and technical definition is used for each service:
- RPO – Recovery Point Objective: Defines the maximum age of the restored data after a failure.
- RTO – Recovery Time Objective: Defines the maximum time to restore the service.
- WRT – Work Recovery Time: Defines how long it takes the recovered service to be brought into Production and begin serving customers again.
- MTD – Maximum Tolerable Downtime: Sum of the RTO and WRT, which is the total time required to recover from a disaster and start serving the business again.
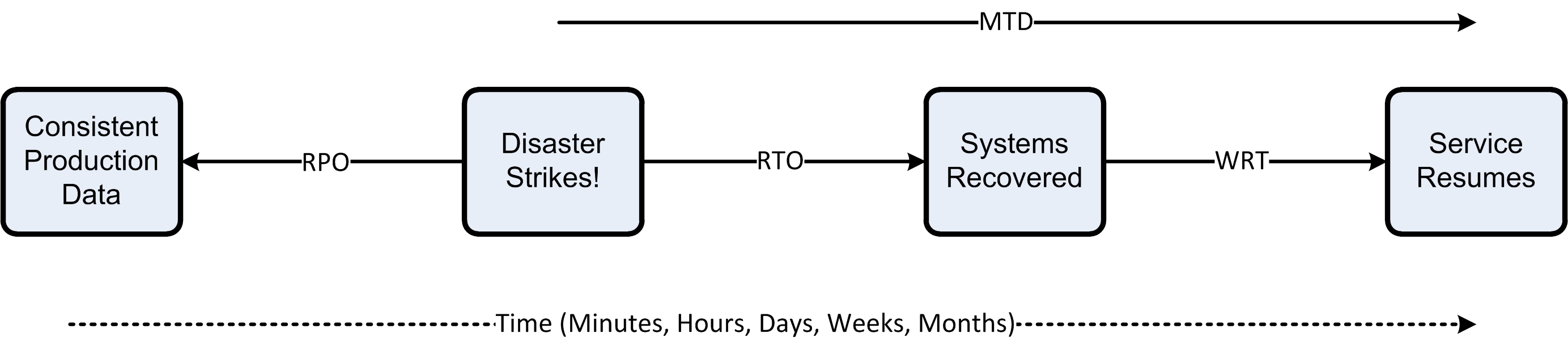
When translating nines of availability into RPO, RTO, WRT and MTD, they could look like this:
- Two 9’s – 99% = RPO 24 hours / RTO 24 hours / WRT 12 hours / MTD 36 hours
- Three 9’s – 99.9% = RPO 8 hours / RTO 6 hours / WRT 2 hours / MTD 8 hours
- Four 9’s – 99.99% = RPO 15 minutes / RTO 40 minutes / WRT 10 minutes / MTD 50 minutes
- Five 9’s – 99.999% = RPO 5 minutes / RTO 3 minutes / WRT 2 minutes / MTD 5 minutes
What are you Protecting Against?
If you do not understand the risks, then you cannot protect against them. Make sure you fully define this. The most common failure scenarios you should protect against are:
- Single Point of Failure (Hardware or Software) – this is failure within the data center and normally protected with High Availability mechanisms such as Application Clustering, Database Clustering and Load-balancing.
- Single Site Failure – your main data center experiences a complete failure that renders it unusable (natural, man-made, accidental disaster).
- Accidental Deletion of Data – an administrator accidentally “fat fingers” a database, disk, datastore, etc. which may or may not be replicated to the remote site.
- Malicious Deletion of Data – an administrator deliberately targets a mission critical system and deletes data which is replicated to the remote site. This is the most difficult to protect against and most difficult to recover from.
Backup Schedule
Backups are mandatory for SMB and Enterprise systems, the only question is the backup type, backup frequency, retention period and restoration time. The major backup types are:
- Image level – crash consistent copy of the entire Guest OS (vmdk or entire NFS Volume/Meta-LUN).
- Application Consistent – backup agent within the OS
- Database Consistent – backup agent within the OS
- File System – crash consistent copy of parts of the Guest OS (backup agent within the OS).
- Database Log Recording – separate DB server configured with Log Shipping.
Recovery Times
You need to make sure that you can restore the data to meet the RPO within the RTO:
- Image Restore – should take seconds.
- Application Consistent Restore – should take minutes.
- Database Consistent Restore – should take minutes.
- File System Recovery – should take minutes.
- Database Log Replay – should take minutes.
- Site Failover – should take minutes or hours depending upon Runbook automation.
If you have four or five nines of availability, then you should seriously consider using database logging to restore within your RPO (via log replay after the DB is restored). This will save having an aggressive backup schedule.
Whatever media / mechanism you use, you must ensure (through testing) that the entire restore process to meet the RPO takes less time than the RTO.
Runbooks
The Runbook is the procedure that describes how to switchover, fail-over and fail-back. Using a manual Runbook for two and three 9’s of availability is possible. However, four 9’s and above require Disaster Recovery Automation, where workflows and scripts control the Runbook process. Otherwise you will exceed your RTO due to the time it takes to execute multiple Runbooks by hand. The Runbook is the procedure that puts the Disaster Recovery Plan into effect.
Operational Complexity
You can clearly see that the more 9’s of availability you have to design for, the more complicated and expensive your design will be. If budget is a major constraint, you will have some requirements conflicts that you will need to resolve.
Service Access
Make sure you configure the DNS Time-To-Live (TTL) and Global Site Load Balancer (if used) to behave correctly. In particular, the DNS TTL must be less than the RTO period.

How could a discussion of “availability” in the enterprise not include application-level high availability options like clustering?
Hello Anonymous, This post covers the impact that Recoverability has upon Availability. The High Availability mechanisms are touched upon in the “What are you protecting against?” section, but is not the focus of the article. Thank you for taking the time to read and comment. Cheers, Rene.
Very well explained! Thanks a lot for sharing!
Excellent post Rene thank you.