 This post is applicable to customers using the VMware vCenter Server Appliance (vCSA) 6.7.
This post is applicable to customers using the VMware vCenter Server Appliance (vCSA) 6.7.
Problem:
- vCenter Server Appliance 6.7 deployed and in use.
- Login to vSphere Client: https:// <IP Address or hostname of vCenter Server>
- vSphere Client System Configuration reports Node Health is Degraded. Access this page from Administration, Deployment, System Configuration.
- Login to vCenter Server Appliance VAMI: https:// <IP Address or hostname of vCenter Server>:5480
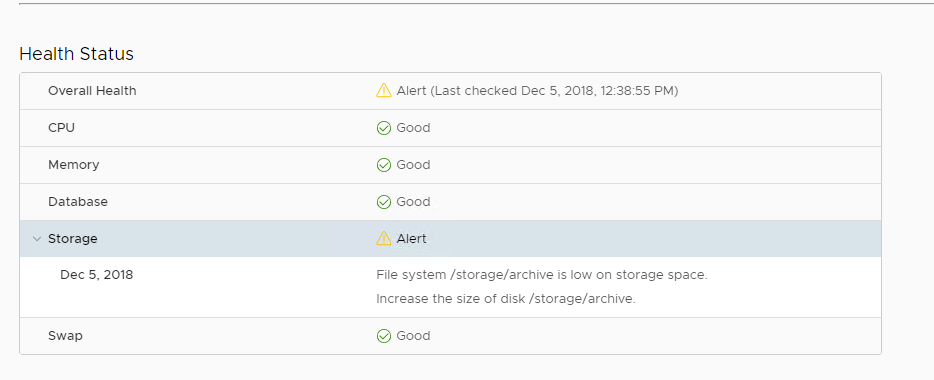
- vCenter Server Appliance VAMI Health Status reports an Alert for Storage: “File system /storage/archive is low on storage space. Increase the size of the disk /storage/archive.” Access this page from Summary, Health Status.
- VMware has not created an updated KB article explaining how to remediate this particular issue.
Solution:
- SSH into the vCSA and login as root and execute the “shell” command to get shell access.
- Run the “df -h” command and verify the “/storage/archive” mount is at 90+% of use.
- Access the vCenter Server that the vCSA instance is running on and increase Disk 13 of the vCSA VM Hardware by a significant amount.
- In the SSH session to the vCSA, run the autogrow script “/usr/lib/applmgmt/support/scripts/autogrow.sh”.
- Run the “df -h” command and verify the “/storage/archive” mount Use percentage has decreased.
- After some time has passed, verify the vSphere Client System Configuration Node Health is “Good”.
- Verify the vCenter Server Appliance VAMI Health Status for Storage is “Good”.
Background:
In vSphere 6.5, the vCenter Server Appliance has 12 vDisks, in vSphere 6.7, this has increased to 13. The 13th disk is used for the /storage/archive volume.




![]()

My vCenter is 6.7 build 11338799. I had to increase disk 4 from 50GB to 90GB. Increasing the size of disk 13 caused /storage/dblog to be increased.
According to https://kb.vmware.com/s/article/57829 this fix appears to be wrong – /storage/archive is *meant* to fill up
not what it says. ‘the /storage/archive partition can be full by design’. Can does NOT imply should.. I don’t agree that systems ‘automatically’ fix themselves. Too many times I have been victim that services should rotate logs or delete older entries.. not doing it again. Therefore if a volume is FULL it should be increased regardless of what automated batch files *SHOULD* address the issue.
I would agree with that, a system should be self-healing – VMware struggles with that.
Thanks a lot solve my case