This week, Nutanix .NEXT 2020 is being held as a digital event due to COVID-19. This combines the traditional US and EU .NEXT programs into one event.
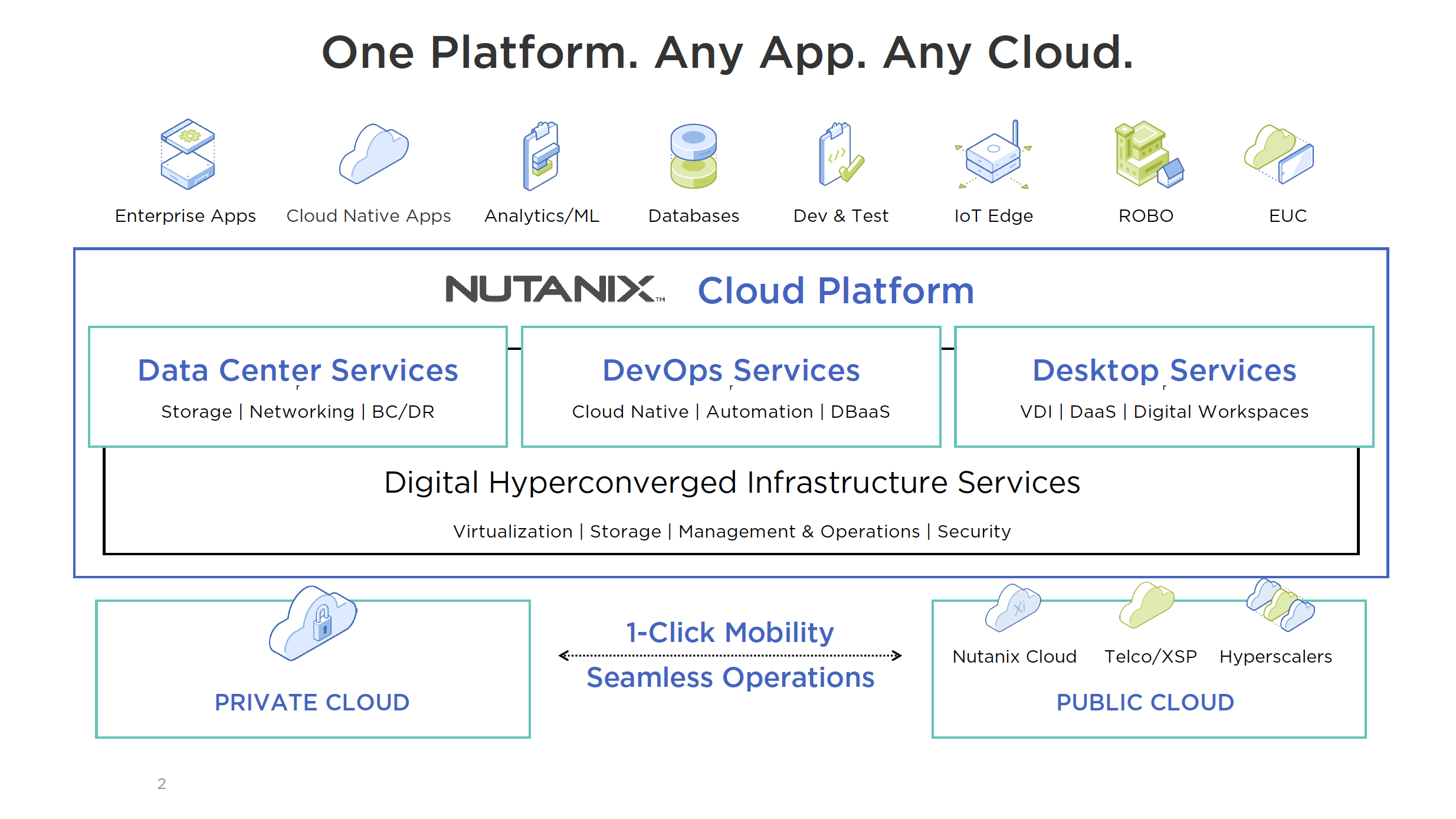
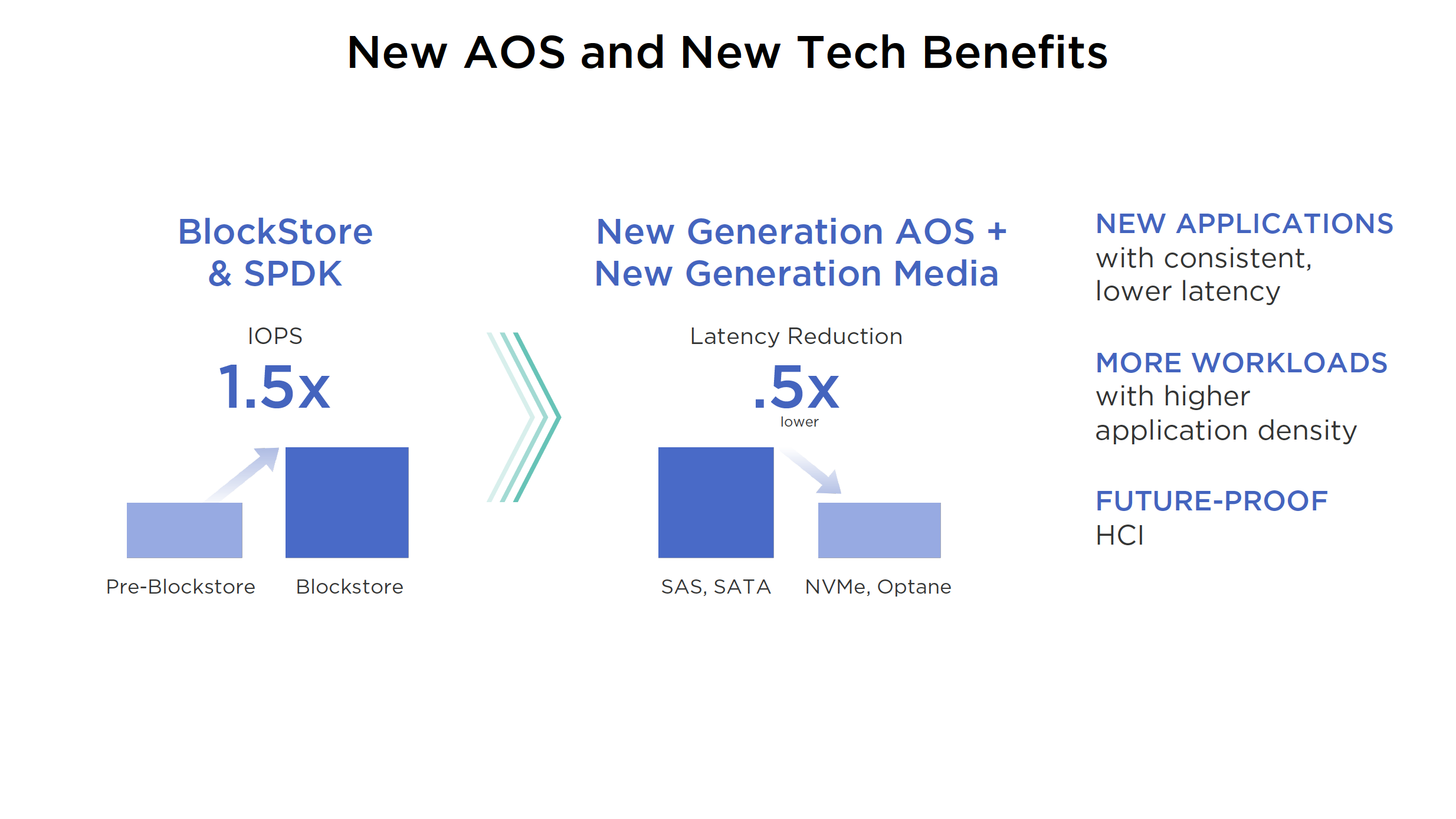
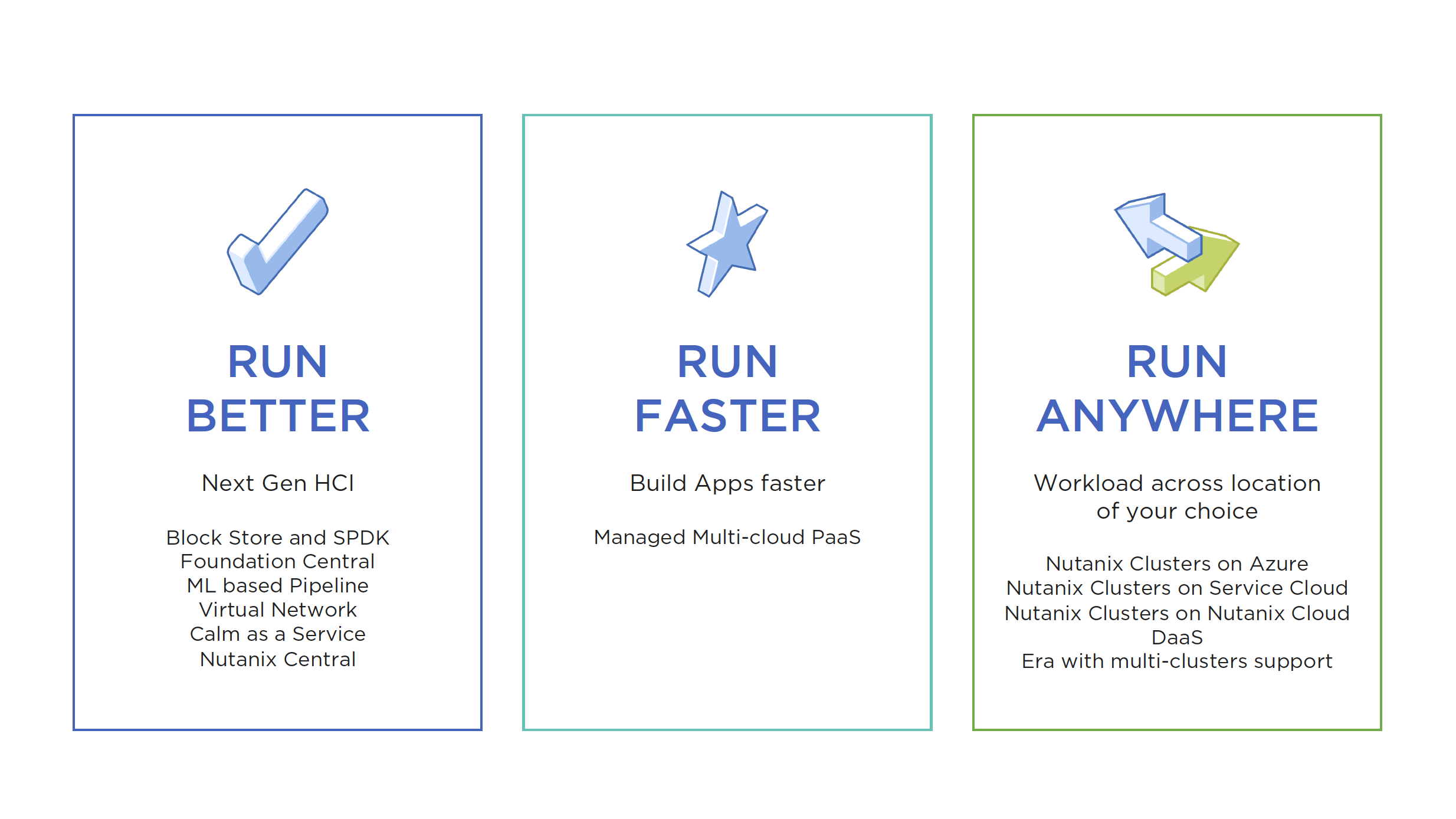
Nutanix Core is the leader in the HCI market. With that being said, Nutanix is certainly not resting on its laurels and continues to innovate in that space with the new BlockStore/SPDK and Optane announcements. They continue to innovate and blaze a trail for the competition to follow. Moving the governance/security module from Xi Beam to Flow in Prism Central is an interesting move. Consuming this service from Prism Central will increase adoption I think. VPCs on-prem (along with Flow) is beefing up the Nutanix offering to complete in the Network Virtualization market, which was always a hole in their game.
The announcements:
- Foundation Central will support 50K VMs and 500 Clusters
- Self Tuning feature to view and resolve application issues
- New licensing tier: Prism Ultimate – App Insights and Cost Showback, Metrics to drive business efficiency and new tier to drive AI Ops
- AOS performance improvements with Block Store, SPDK and Optane support
- Deploy Files & Objects anywhere from Prism Central
- 60 second RPO support for Files & Objects
- Cold Data Tier support for Files & Objects
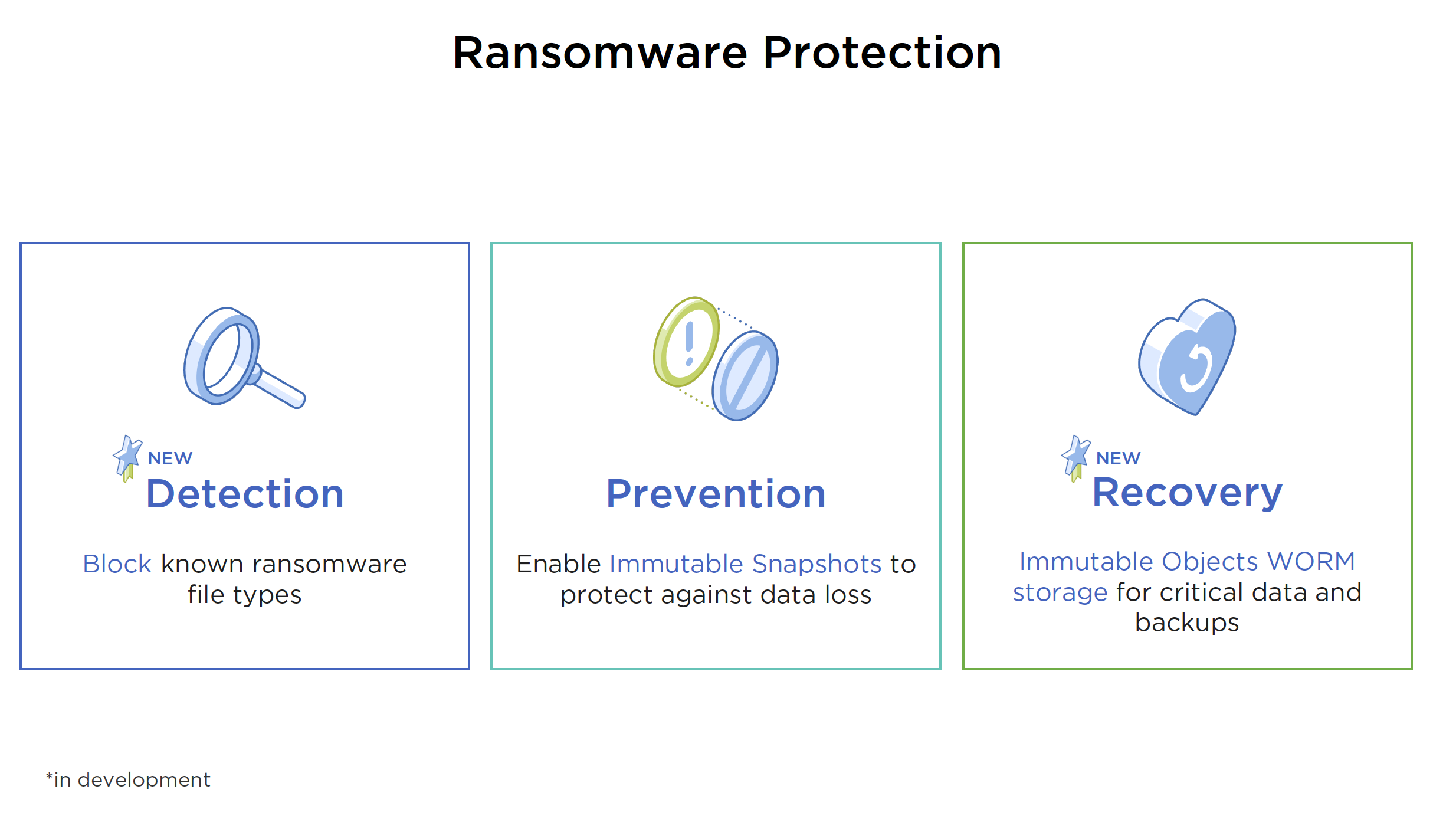
- Ransomware Protection with Detection, Prevention (immutable snapshots) and Recovery (immutable objects WORM storage)
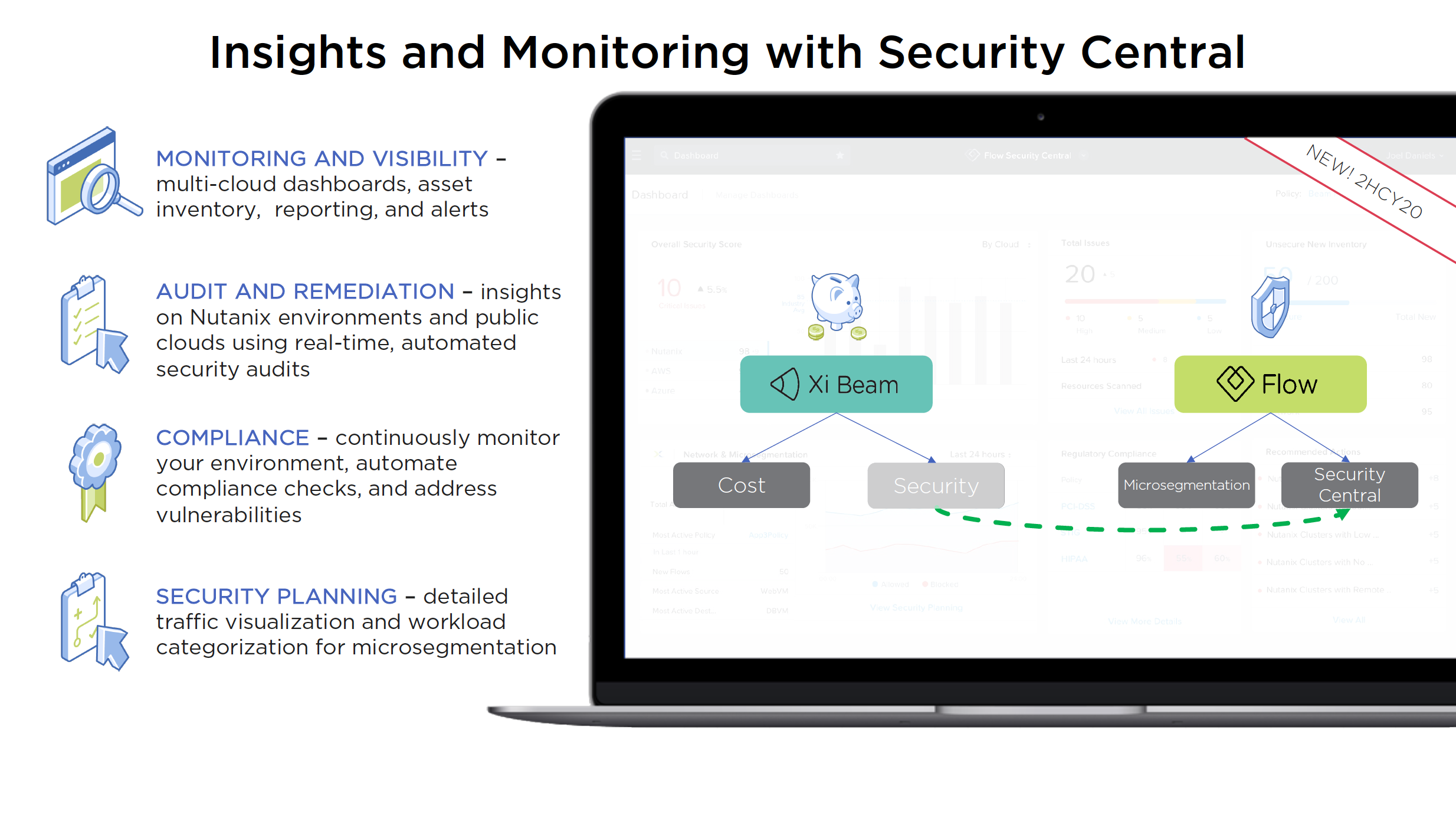
- Security Central with security module from Beam moved to Flow (in Prism Central)
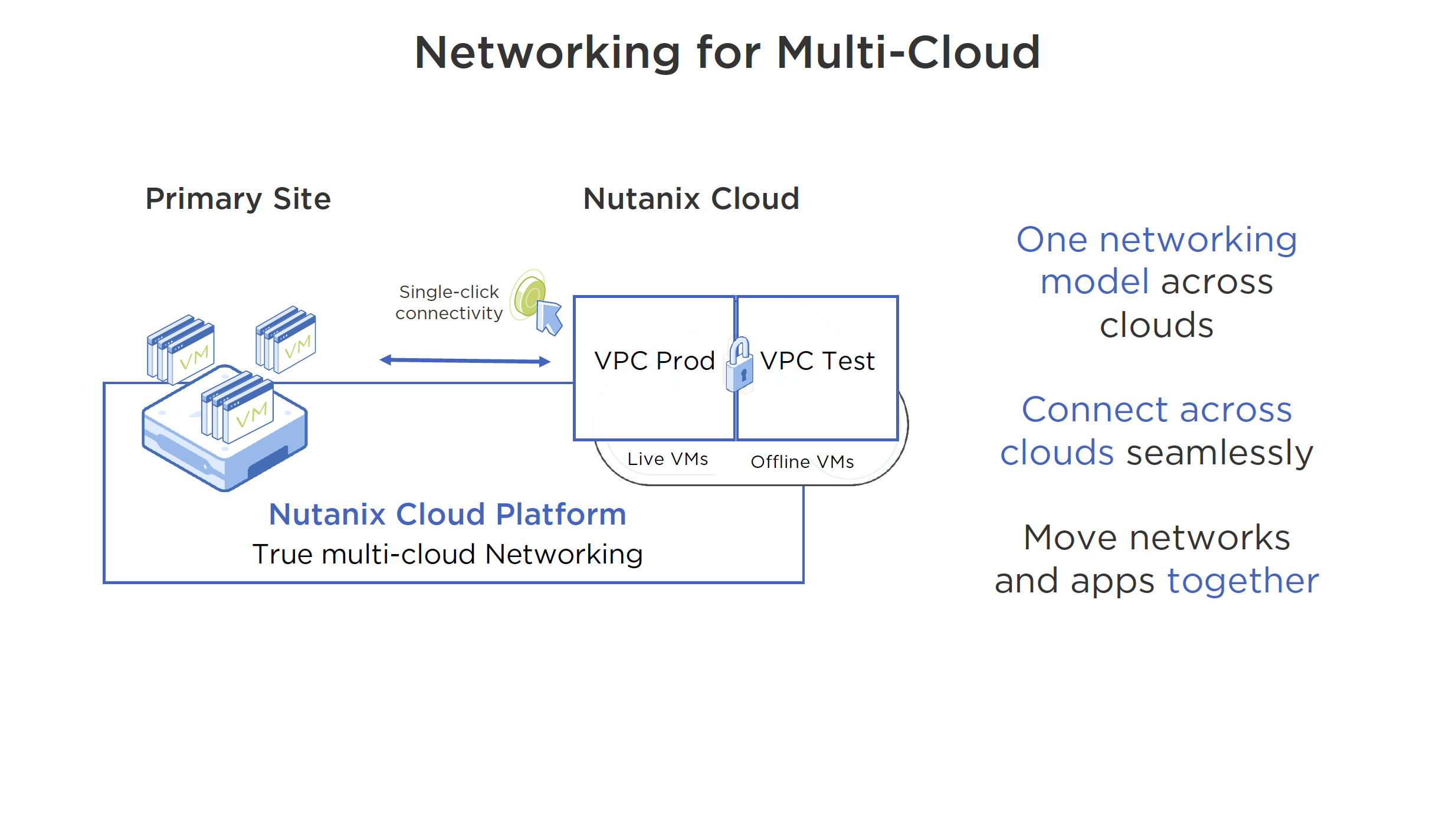
- VPCs On-Prem with AHV (Layer 2 extension over Layer 3 networks)
- Nutanix Central announced (Multi-Cloud DevOps SaaS)
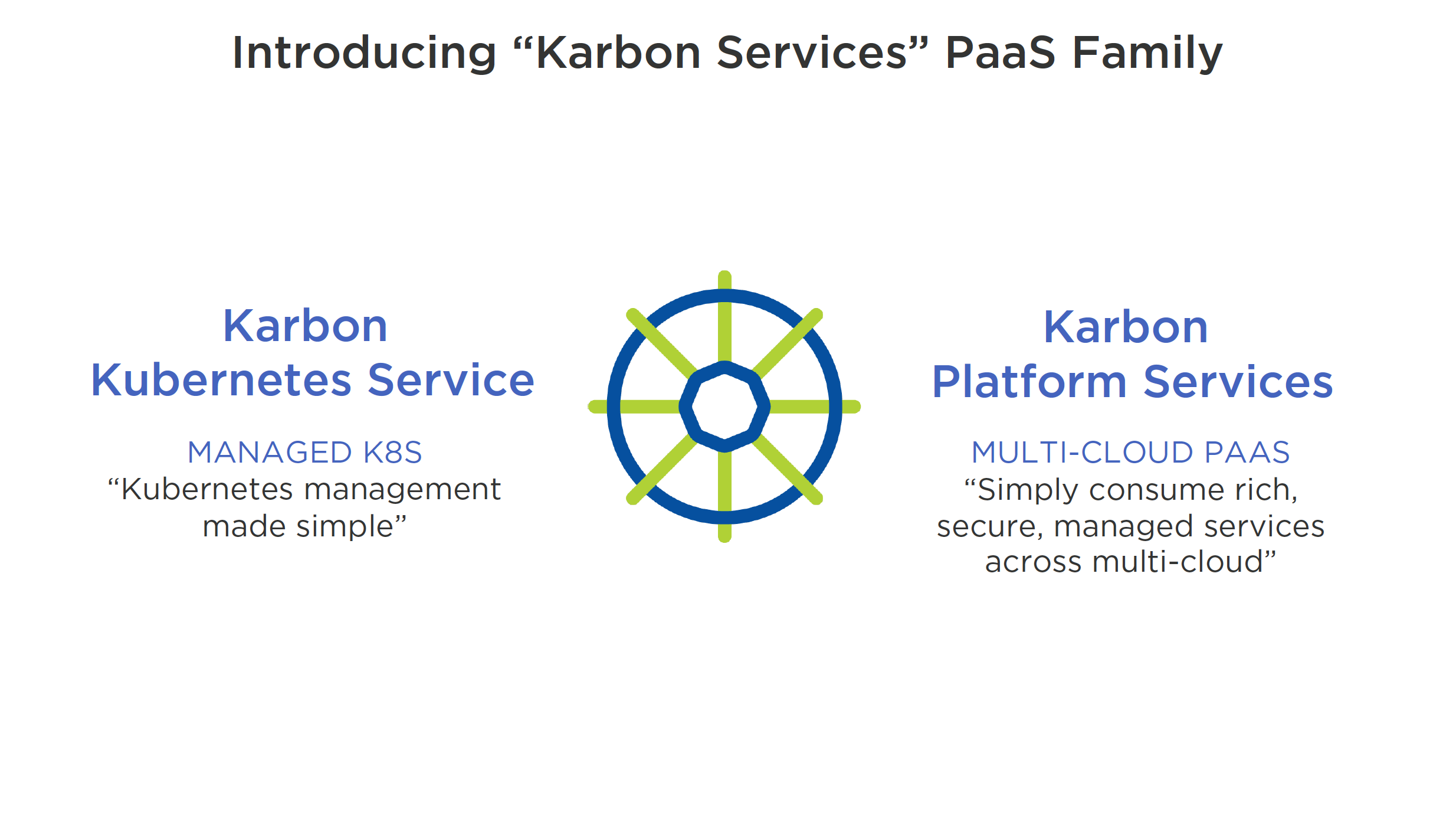
- Karbon Services PaaS Family announced (Multi-Cloud PaaS)
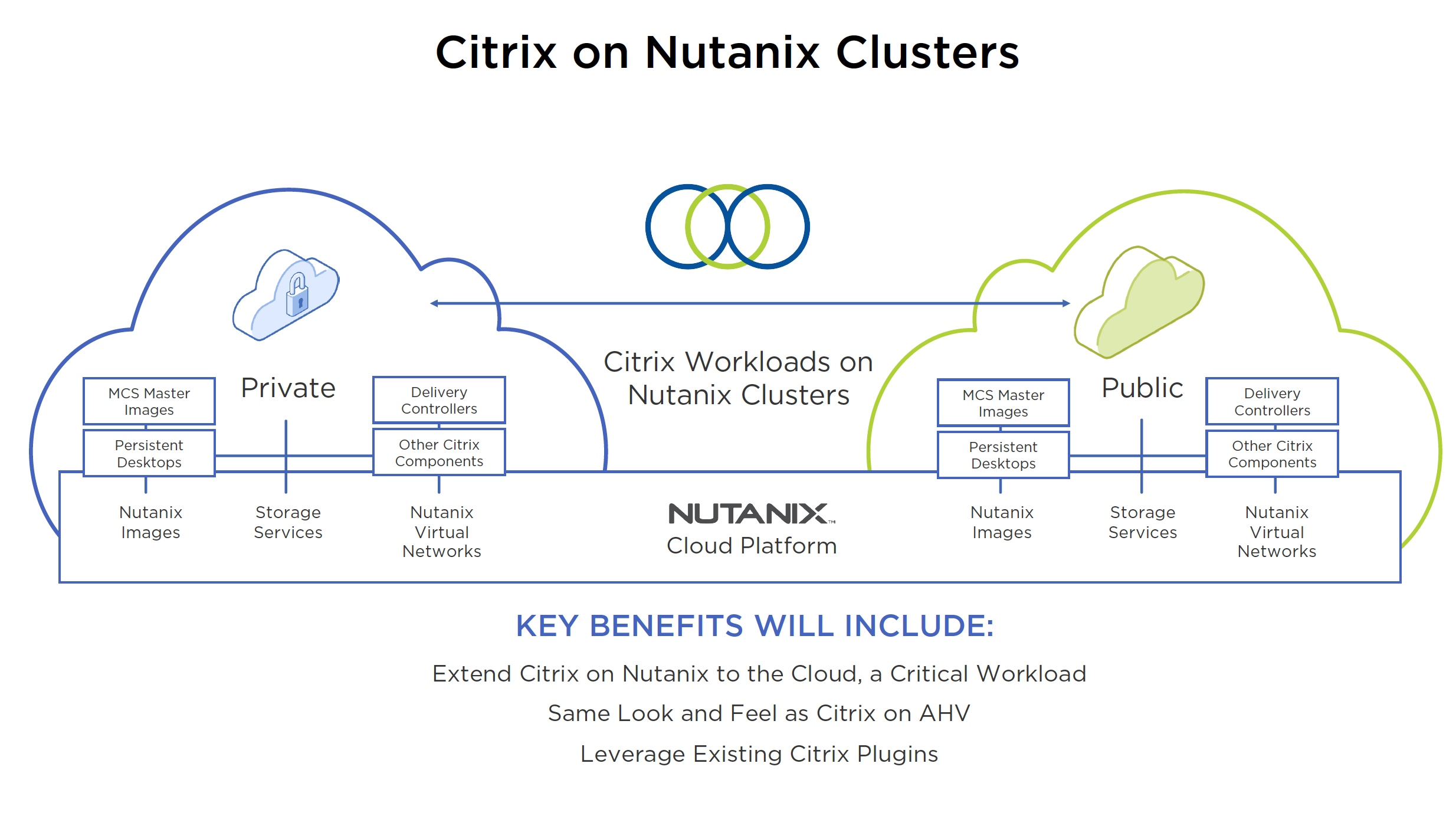
- Citrix on Nutanix Clusters announced
- Nutanix Era multi-cluster support announced
- Nutanix Clusters on Azure announced
- Calm-as-a-Service announced
- Service Providers running Nutanix software
Screenshots: